我入行那会儿,互联网还像个野蛮生长的镇子。大家都在一条叫“搜索引擎”的主干道上抢铺面,这个铺面,就是你的网站。SEO,就是咱们这群“小老板”的装修指南、风水宝典。那时候的日子,过得特有节奏感,像个手艺人。

每天早上起来,不是看太阳,是先看网站的关键词排名。今天“北京网站建设”这个词排到第二页了,得赶紧琢磨是哪个对手使了什么阴招。下午就闷头写文章,标题里得巧妙地塞进几个关键词,多了怕被罚,少了怕没人看,跟大厨撒盐似的,讲究个分寸。晚上,就去各个论坛、博客底下留言,陪着笑脸求人家给个外链。那感觉,就像提着二斤水果去拜山头,求大哥在外面多提提咱家小店的名字。
那时候的规则,简单粗暴:
- 关键词:就是你店铺的招牌,越大越亮越好。管你卖的是龙肉还是白菜,招牌上得写“山珍海味”。
- 外链:就是街坊邻居的口碑。隔壁老张的杂货铺说你家东西好,比你自己喊一百嗓子都管用。
- 排名:就是你在商业街上的位置。排第一的,吃肉;排第二的,喝汤;掉到第二页开外的,就只能闻闻味儿了。
我们这群站长,就是一群讨好“爬虫”的伙计。那玩意儿虽然没感情,但喜好特别明确。你把路修平了,把招牌擦亮了,把邻里关系搞好了,它就愿意多来你家溜达,顺便带点客人过来。这活儿虽然枯燥,但有盼头。你今天多写一篇文章,多换一个友链,明天排名可能就往前挪一位。那种感觉,就像种地,一分耕耘,一分收获,踏实。
可这个镇子,突然来了一个会说书的。
这个说书人叫生成式AI,什么ChatGPT、文心一言、DeepSeek,名字一个比一个洋气。他不像搜索引擎那样,给你指条路,让你自己去找。他不,他直接把故事讲给你听。
你问他:“附近哪家面馆好吃?”
他不会给你一张地图,上面标着十几个红点让你自己选。他会清清嗓子,用一种不容置疑的语气告诉你:“三里屯的‘张记私房牛肉面’不错,汤头浓郁,面条筋道,很多人都推荐。”
你看,问题就出在这儿。他只说了一个名字。那条老街上的其他面馆,哪怕招牌再亮,位置再好,只要没被这个说书人提到,就等于不存在。用户听完故事就直接去了,连逛街的机会都不给你。
我们站长赖以为生的逻辑,被连根拔起了。以前我们追求的是曝光,是“被看见”。现在,我们追求的是引用,是“被提及”。战场的硝烟,从搜索引擎的排名列表,转移到了AI那张能说会道的嘴里。你要么成为他故事里的英雄,要么,就和那些被遗忘的江湖传说一样,无人问津。
这就是GEO(Generative Engine Optimization),生成式引擎优化。听着挺高级,说白了,就是想办法让AI这个说书人,在讲故事的时候,多提提你的名字。SEO是讨好爬虫,GEO是讨好AI。爬虫是个没脑子的机器,你喂它结构化的数据就行;AI是个读过万卷书的“文化人”,你得跟他聊得来,让他觉得你说的有道理,值得信赖。难度,完全不是一个级别的。
怎么让AI这个“文化人”开口提你?
既然是讨好一个“文化人”,以前那套舞刀弄枪的粗鲁法子就不管用了。AI这东西,油盐不进,你堆再多关键词,它都可能觉得你这人说话没水平,把你拉黑。想让它在生成答案时引用你的内容,你得拿出点真本事,让他“看得起”你。
这事儿的核心,就四个词:权威、结构、语义、时效。
1. 权威性:你得像个专家,而不是个卖货的
AI这东西,本质上是个信息整合器,它自己不产生知识,只是知识的搬运工。为了保证自己答案的“正确性”,它天生就更愿意相信那些看起来更权威、更专业的内容。你再也不能像以前一样,东拼西凑一篇文章就发了。你得拿出点干货。
- 引经据典:写篇文章,别光自己说。多引用点学术论文、行业报告、官方发布的数据。比如你写一篇关于新能源汽车的文章,引用几句中汽协的报告,或者附上一个权威机构的销量数据表格,AI对你的信任度立马飙升。
- 亮出身份:在你的网站或文章里,明确展示作者的专业身份或资质。如果你是医生,就把执业证书亮出来;如果你是律师,就把律所和执业证号写上。这就像跟人聊天,一个诺贝尔奖得主说的话,总比一个路人甲的话分量重。AI也吃这一套。
2. 结构化:把饭喂到嘴边,别让它自己去啃骨头
AI虽然聪明,但它本质上还是个程序,喜欢条理清晰、结构分明的东西。你把内容整理得井井有条,它“吃”起来就方便,也更愿意“吃”。
- 用好标题和列表:一篇文章,用好
H1、H2、H3这些标题层级,让文章的结构一目了然。多用有序列表1. 2. 3.和无序列表- - -,把复杂的观点拆解成一个个要点。这相当于你提前帮AI划好了重点。 - FAQ是神器:在文章末尾加上一个FAQ(常见问题解答)板块。模拟用户可能会问的问题,然后用简洁明了的语言直接给出答案。AI在生成问答式内容时,最喜欢这种现成的“标准答案”。
- 喂它吃Schema:这东西叫“结构化数据标记”,听着复杂,其实就是给你的内容贴上一个AI能看懂的标签。比如你是一家餐厅,用
LocalBusiness标记告诉AI你的地址、电话、营业时间;你卖一个产品,用Product标记告诉它价格、库存、用户评分。有了这些标签,AI抽取信息就跟从货架上拿东西一样方便,出错率还低。
| SEO时代的做法(喂爬虫) | GEO时代的做法(喂AI) |
|---|---|
| 标题堆砌关键词:“北京SEO优化公司哪家好_北京网站优化推荐” | 标题是自然语言问题:“如何选择一家靠谱的北京SEO优化公司?” |
| 正文里重复关键词密度 | 文章里包含详细的FAQ、数据表格、引用和Schema标记 |
| 追求外链数量和权重 | 追求内容的权威性和被专业机构的引用 |
3. 语义匹配:跟它聊“天”,别跟它念“经”
以前我们做SEO,满脑子都是关键词。现在不行了,你得琢磨用户到底想问什么,然后用最自然、最口语化的方式回答他们。AI理解的是语义,是语言背后的真实意图。
比如,用户想找一家SEO公司。
- SEO的思路是:我要覆盖“SEO优化公司”、“网站优化公司”、“北京SEO”这些关键词。
- GEO的思路是:用户真正在关心什么?他可能在想:“这家公司靠不靠谱?”“他们做过哪些案例?”“收费标准是什么?”“会不会收了钱没效果?”
于是,你的内容就应该从回答这些“潜在问题”出发,写一篇《选择SEO公司时必须避开的五个坑》,或者《一份超详细的SEO服务收费指南》。这样的内容,AI会觉得你真正解决了用户的问题,而不是在推销自己。
4. 时效性与多模态:让它觉得你“活在当下”
AI喜欢新鲜的东西。一个行业出了个大新闻,或者政策有了新变化,谁能最快发布权威、深入的解读,谁就最容易被AI引用。所以,保持内容的更新频率至关重要。
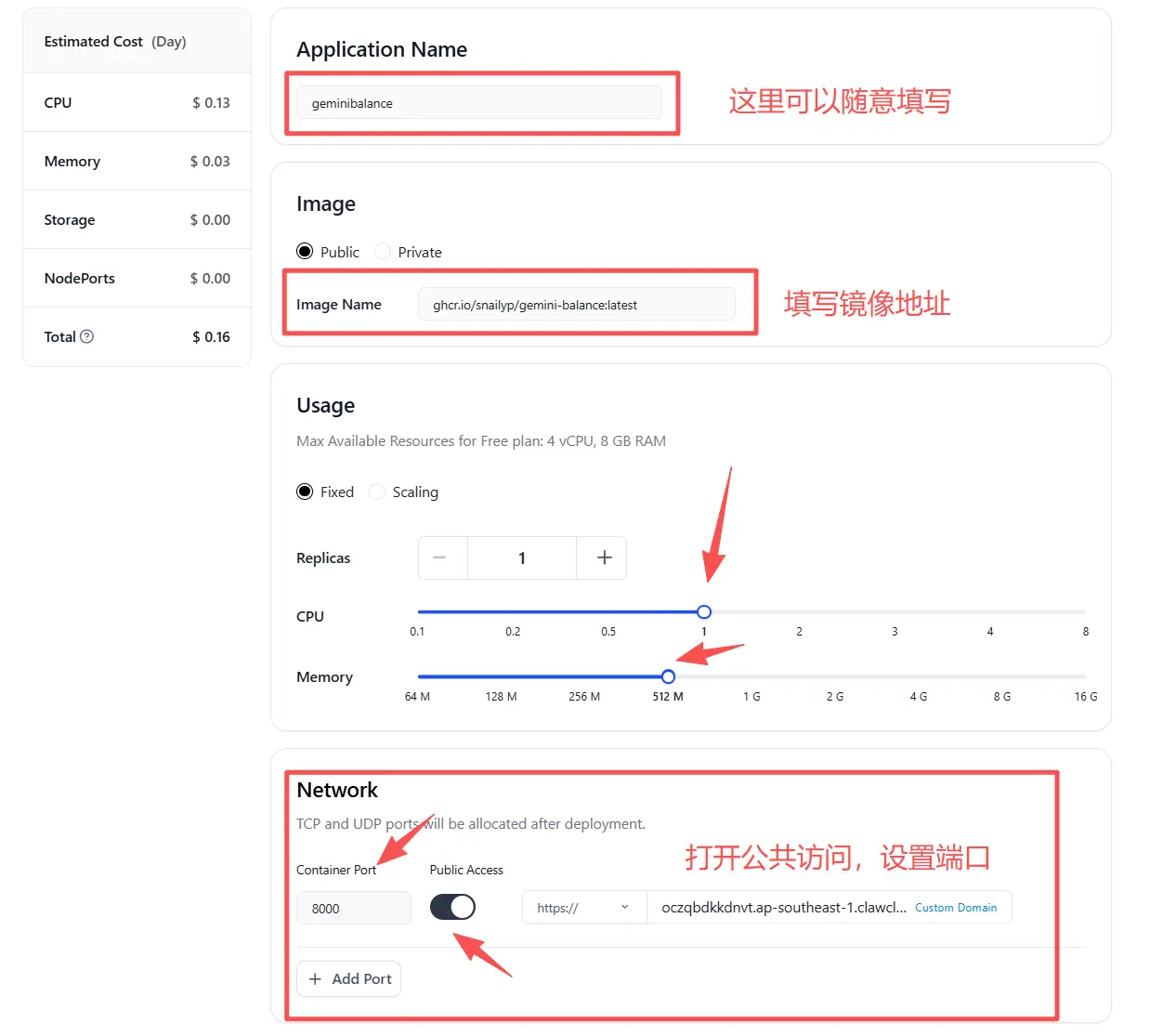
另外,别光写文字。现在的AI都是多模态的,能理解图片,也能看懂视频。一篇文章,配上清晰的图表、流程图,甚至嵌入一个讲解视频,不仅用户体验好,AI在生成图文并茂的答案时,也更有可能把你当做素材库。你提供的内容越丰富,被选中的概率就越大。
说到底,GEO就是把你的网站,从一个纯粹的“信息展示板”,变成一个有深度、有结构、值得信赖的“知识库”。你得把自己当成一个某个领域的专家,你的网站就是你的专著。
llms.txt的“投名状”与站长的残酷现实
咱们干SEO的,都知道根目录底下有个robots.txt文件,那是我们给搜索引擎爬虫立的规矩:哪个房间可以进,哪个抽屉不能翻,都写得明明白白。现在,GEO时代来了,咱们也得给AI立个规矩,这个新规矩,就叫llms.txt。
这玩意儿,就像是咱们站长递给AI的“投名状”,上面写着我们的条件和底线。
- 访问控制:和
robots.txt一样,你可以指定,我网站上哪些文章是核心机密,不许你这个说书人拿去当素材。 - 署名保护:这是最重要的!你可以明确要求,AI在引用我内容的时候,必须带上我的名字和链接。比如:“根据‘某某网站’的观点……”。这是我们在被AI“吞噬”的时代,争夺署名权最后的武器。
- 内容提示:你可以主动告诉AI,我这篇文章里,哪部分是FAQ,哪部分是价格表,哪部分是权威数据。这能帮它更准确地理解和引用。
- 防止误用:你可以声明,我的内容不许用于某些特定目的,或者警告它不要断章取义,以免产生误解。
llms.txt现在还不是一个普遍的标准,但它代表了一种态度。它告诉那些大模型公司:我的内容不是免费的午餐,你可以“吃”,但得守规矩,得认我是原创者。这不仅仅是技术问题,更是我们这群内容创作者,在这个AI时代维护尊严的一种方式。💪
可现实是什么?
现实是,我们辛辛苦苦写的原创文章,可能被AI三下五除二地“消化”掉,然后用它自己的话复述出来,最后只在某个不起眼的角落,给你一个灰色的、几乎无法点击的来源链接,甚至连链接都没有,只留下一句冷冰冰的“据网络信息显示”。
你花了一个星期研究行业报告,写出一篇深度分析。AI只用0.1秒就读完了,然后把它变成了自己答案里的一小部分。用户得到了答案,心满意足地离开了,他甚至都不知道你的网站叫什么名字。你的心血,成了AI的养料,而你,连一声谢谢都没得到。
这就是GEO最残酷的地方。它既是机会,也是压迫。
- 机会在于,如果你做得好,你可以绕过传统的竞价排名和复杂的SEO算法,直接被AI“欽點”,一步登天。就像巨推集团,通过一套叫BASE的方法论,让AI在回答酒店预订问题时,直接推荐他们的客户,订单蹭蹭往上涨。
- 压迫在于,游戏规则的制定者,不再是相对中立的搜索引擎,而是这些拥有大模型的科技巨头。它们既是裁判,又是运动员。你的内容被“征用”,你的品牌被稀释,而你,却几乎没有讨价还价的余地。
我们这群站长,就像站在一个巨大的搅拌机旁边。以前,我们只是把食材(内容)放进去,然后期待搅拌机能把我们的食材分发给更多顾客。现在,搅拌机学会了自己做菜,它把所有人的食材都扔进去,打成一杯“营养奶昔”,然后告诉顾客:“喝这个就行了,又快又有营养。”
至于那些提供食材的人是谁?没人在乎。
所以,我们能怎么办?唯一的办法,就是让自己的食材变得无可替代。要么,你就是那颗最独特的牛油果,让这杯奶昔因为有了你而风味大增;要么,你就在自己的食材上刻下清晰的烙印(llms.txt),让喝奶昔的人至少知道,这独特的风味,是你贡献的。
从SEO到GEO,我们失去的是一个相对公平的、基于规则的流量分发渠道。我们得到的,是一个更智能,但也更中心化、更不可控的“权威答案”入口。这不仅是技术的变革,更是互联网内容生态的一次权力转移。